通过分析不同的分类,发现不同的分类的页面和接口不是统一的,所以需要针对不同的分类编写对应的逻辑。以美食分类为例
获取所有城市
美团美食业态的访问地址为,浏览访问时会自动定位城市,所以进行爬虫时先把城市的数据爬下来,在切换城市界面解析一下html就可以获取到所有城市以及对应的code,随后就可以循环所有的城市,一个城市一个城市地爬。
获取所有城市下的商圈
美团以分页显示商家,每页32条记录,而且最多显示32页,所以如果以城市为单位去爬,只能爬到少量的数据,需要缩减区域即增加过滤条件去向后台请求数据。通过观察,基本所有的商圈的商家数量都在32*32之内,所以以商圈为单位去爬还是比较合理的。层次为:城市->区域->商圈,循环所有城市组装并解析所有城市的所有区域下的所有商圈:
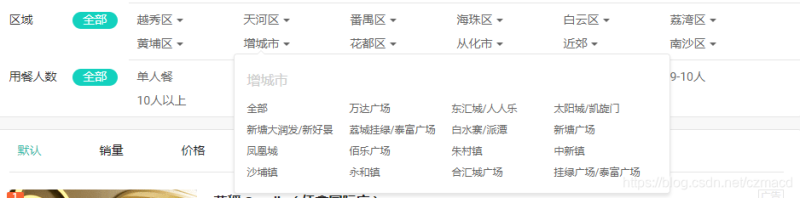
本来想解析页面html获取商圈的,但是只有当鼠标移动到某一个区域上面才会出现上图下拉的商圈数据,其实所有商圈的数据(基本包含了当前页面的所有数据)已经保存在当前页面的js脚本中,通过正则表达式很容易得到json结果

格式化后
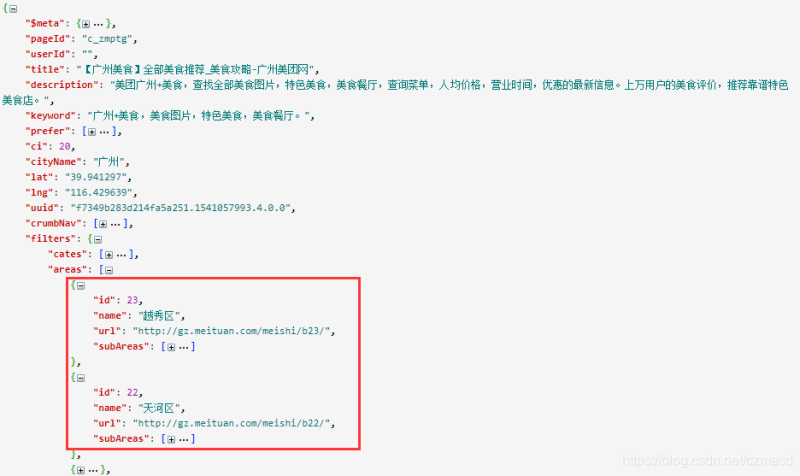
提取所有的商圈id(对应subAreas)并保存与城市的关联关系

获取所有商圈下的商家
在上一步已经拿到了所有商圈数据,接着就是以商圈为单位分页获取每个商圈下的商家数据,有两种方式
- 和获取商圈数据一样,请求页面,解析从js中解析得到当前分页的商家数据,格式为
- 直接请求http接口只获取到商家分页列表的json数据:
第二种方式需要解析的生成,其中两种方式都可以通过字段来判断是否存在下一页, 这里需要注意的是,虽然拿到了商家信息,但手机号码需要进入到商家详细界面才可以得到
获取商家的手机号码
在分页获取获取商家列表的时候得到了商家id,然后得到美食商家的详细地址,但是少量数据可能是不正确的,需要有些商家出现在美食列表中,但是按这个详细地址在浏览器访问时会跳转到另一个分类的地址,例如->,这样用代码来请求数据时可能会得到错误的结果,不过只有少部分数据会这样,还有一个问题是,美团的商家数据变更得比较快,可能隔几天某些商家就不在美团平台里了。
模拟生成
在上面获取商家列表的时候,以请求接口的方式时url需要带上,它时每次在浏览器发请求时动态生成的,由于带上了时间戳,每个几分钟后就失效,所以需要自己实现生成方法。实现的代码在rohr.min.js文件中的reload方法,由于加密混淆了,基本没法跟踪逻辑,最终还是把js文件放到selenium环境中直接调用方法,输入带上参数的请求url,返回的就是值
美团还有一个反爬手段就是需要进行图片码验证(数字字母),当长时间请求且请求太过频繁,会被检测到并且重定向到verify页面

网上也有介意说一些识别验证码的方法,例如第三方打码平台,OCR库,和使用大量样本训练机器学习模型,简单地使用百度aip和tesseract尝试都没效果,还不如搞个代理池(网上的免费代理基本没啥用,后面也用Tor+polipo搭了个代理网络),目的也是为了学习爬虫一些基础知识而已,这座大山也没翻过去(有翻过去的大大给点提示)。
思路跟美团的相似,但是比美团更为复杂点,通过观察发现大众点评的数据比较多,,而且每页15条记录,最多显示50页,很多商圈都超过15*50这个数量,所以需要更细化,最终细化到每个商圈下的分类:城市->区->商圈->分类
获取所有城市
在切换城市界面可以解析html获得所有城市数据
获取所有城市商圈
先要访问每个城市的美食列表页面,从页面中获得区的数据

然后还要循环访问第一个行政区才能拿到商圈,这里多了一层访问,不像美团区(area)和商圈(subArea)数据是一次请求取得

最终想要的是红圈中的商圈数据,其中代表美食分类,代表商圈

获取所有商圈的美食分类
在获取到商圈数据后,接着需要获取商圈下的美食分类,每个商圈的分类是不一样的,所以要循环所有的商圈,而且美食的分类还分为一级分类,二级分类,这里细分到一级分类

最终得到以下数据,格式:

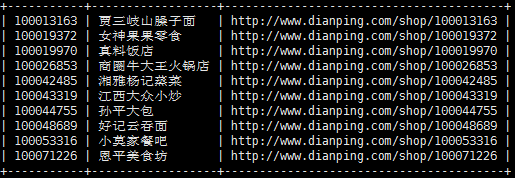
获取美食商家
以商圈的每个分类为单位分页获取商家的数据,与美团一样手机号码这些信息只在详细页面,在分页页面先获取商家id(),名称和详细页面url。在分页页面和详细页面点评都做了反爬,都是通过css来控制一些字和中文的显示,还好,在分页列表所需的信息都是原始数据
获取商家详细信息
请求上一步的商家详细url获取详细信息,手机号码,地址,评价等这些信息都做了反爬,脑洞也真是够大的,举个栗子:
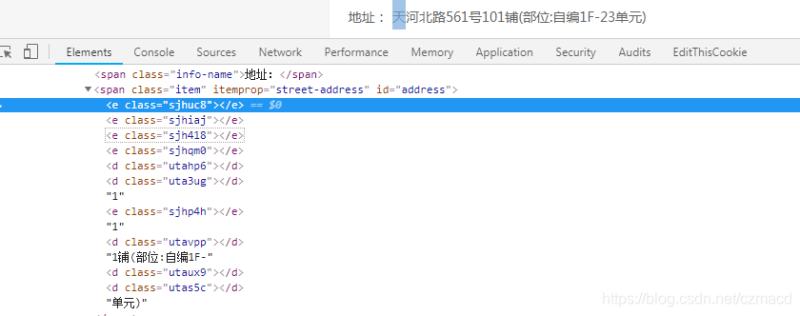
并不是所有字符都做了手脚,只是特定某些字符被使用一个css类来代替了,还可以发现表示是一个中文(准确说是用于地址的一个中文字符),是一个数字,最终所有的原始值就在一个背景图(svg)中,然后通过class控制像素偏移来显示需要的字符,下图是用于地址的字符,只要是地址中包含以下的字符,就用css来控制,而数字、评论等其它也有各自的一张背景图

同一张背景图中的字符都会由具有相同前缀的class表示,更坑的是这些背景图上的字符顺序会变,对应的class也会变(因为css文件是动态生成的),不过有一点不变的是,用于表示地址字符的还是标签,表示号码的还是标签,根据这点就可以从css文件中知道表示地址字符的class是什么前缀,继而可以拿到所有class

这样一来就可以得到class与代表该字符在背景图上的偏移值{‘sjhuc8’:’-322.0px -295.0px’},再根据svg背景图可以计算得到偏移值与字符的映射关系(这两个过程还是挺费工夫的),这样一来在解析html时就可以根据class来获得真实的字符值,每次通过判断css文件是否已经更新,如果更新就需要重新计算映射关系,最终可以得到真实的数据

一些网站通过分析统计的访问次数、频率进而限制爬虫,在爬的过程中出现各种各样的验证方式,技术过硬的话倒是可以正面突破,不要然考虑使用代理来绕过也是一个比较好的方法,网上的公开代理不仅慢而且很不稳定,条件允许的话当然还是购买私有代理最好。
Tor是实现匿名通信的自由软件。其名源于“The Onion Router”(洋葱路由器)的英语缩写。用户可透过Tor接达由全球志愿者免费提供,包含7000+个中继的覆盖网络,从而达至隐藏用户真实地址、避免网络监控及流量分析的目的。Tor不会阻止在线网站判断用户是否通过Tor访问该网站。尽管它保护用户的隐私,但却不会掩饰用户正在使用Tor这一事实。(如果网站对Tor进行了反爬限制,那就凉了)
当使用Tor访问网络时,会选择几个中继作为Tor回路,代理请求并不断加密,虽然隐藏了原IP地址,但爬虫时希望不总是以同一个匿名IP高频访问,所以还需要动态更改Tor回路来改变匿名后的IP
安装Tor核心服务
进入下载页面,选择,下载后解压即可,因为没有界面,所以还需要下载一下tor控制器Vidalia,同样是解压
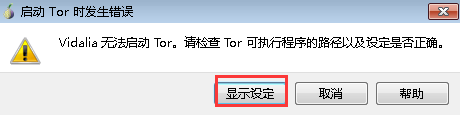
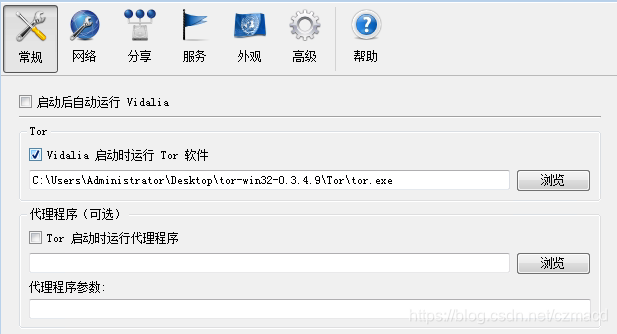
- 进入vidalia目录,打开,首次需要配置Tor可执行程序路径,找到并选择
设置前置代理
在国内需要fq之后才能连到tor网络,刚好平时使用shadowsocks,所以使用它作为前置代理,在vidalia控制页板->设定->网络

确定后返回vidalia控制面板启动Tor
安装配置polipo
Tor的默认代理端口是是9050(vidalia设置->高级->Tor配置文件中可查看),但是是Socks5协议的,编写爬虫程序使用的是http代理,需要使用使用polipo进行转换,下载polipo-1.1.0-win32.zip解压,找到config.sample,添加配置
然后运行,根据输出提示启动了8123端口作为http代理监听端口。配置一下windows网络代理进行验证
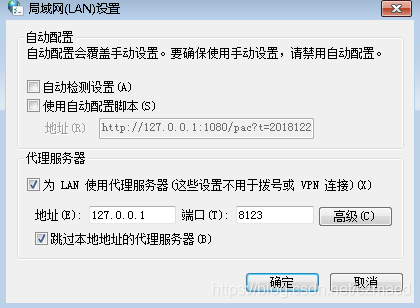
打开浏览器访问一下http://www.ip138.com/,此时已经显示的是外国IP地址
动态切换IP
只要更改了Tor回路,那么就有可能改变IP,可以通过向Tor发送信号可以清理旧的回路切换到新回路
“signal newnym” will make Tor switch to clean circuits, so new application requests don’t share any circuits with old ones.
在设置->高级中可以对tor控制进行相关配置
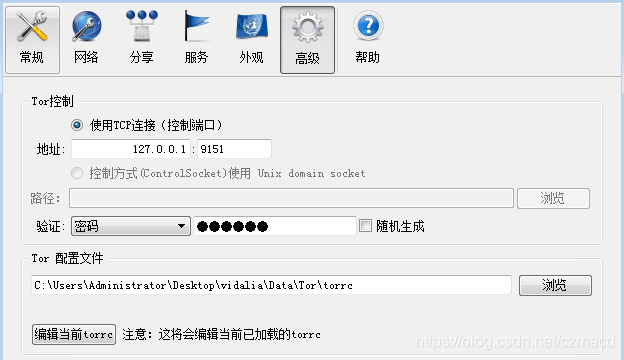
附上相关代码段